

X
Trustworthy Source
PubMed Central
Journal archive from the U.S. National Institutes of Health
Go to source
If this p-value is less than the significance level set (usually 0.05), the experimenter can assume that the null hypothesis is false and accept the alternative hypothesis. Using a simple t-test, you can calculate a p-value and determine significance between two different groups of a dataset.
Setting up Your Experiment

Define your hypotheses. The first step in assessing statistical significance is defining the question you want to answer and stating your hypothesis. The hypothesis is a statement about your experimental data and the differences that may be occurring in the population. For any experiment, there is both a null and an alternative hypothesis. Generally, you will be comparing two groups to see if they are the same or different. The null hypothesis (H0) generally states that there is no difference between your two data sets. For example: Students who read the material before class do not get better final grades. The alternative hypothesis (Ha) is the opposite of the null hypothesis and is the statement you are trying to support with your experimental data. For example: Students who read the material before class do get better final grades.

Set the significance level to determine how unusual your data must be before it can be considered significant. The significance level (also called alpha) is the threshold that you set to determine significance. If your p-value is less than or equal to the set significance level, the data is considered statistically significant. As a general rule, the significance level (or alpha) is commonly set to 0.05, meaning that the probability of observing the differences seen in your data by chance is just 5%. A higher confidence level (and, thus, a lower p-value) means the results are more significant. If you want higher confidence in your data, set the p-value lower to 0.01. Lower p-values are generally used in manufacturing when detecting flaws in products. It is very important to have high confidence that every part will work exactly as it is supposed to. For most hypothesis-driven experiments, a significance level of 0.05 is acceptable.
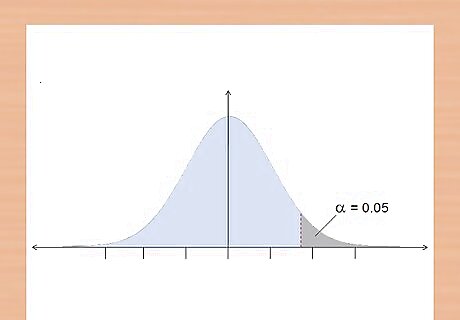
Decide to use a one-tailed or two-tailed test. One of the assumptions a t-test makes is that your data is distributed normally. A normal distribution of data forms a bell curve with the majority of the samples falling in the middle. The t-test is a mathematical test to see if your data falls outside of the normal distribution, either above or below, in the “tails” of the curve. A one-tailed test is more powerful than a two-tailed test, as it examines the potential of a relationship in a single direction (such as above the control group), while a two-tailed test examines the potential of a relationship in both directions (such as either above or below the control group). If you are not sure if your data will be above or below the control group, use a two-tailed test. This allows you to test for significance in either direction. If you know which direction you are expecting your data to trend towards, use a one-tailed test. In the given example, you expect the student’s grades to improve; therefore, you will use a one-tailed test.

Determine sample size with a power analysis. The power of a test is the probability of observing the expected result, given a specific sample size. The common threshold for power (or β) is 80%. A power analysis can be a bit tricky without some preliminary data, as you need some information about your expected means between each group and their standard deviations. Use a power analysis calculator online to determine the optimal sample size for your data. Researchers usually do a small pilot study to inform their power analysis and determine the sample size needed for a larger, comprehensive study. If you do not have the means to do a complex pilot study, make some estimations about possible means based on reading the literature and studies that other individuals may have performed. This will give you a good place to start for sample size.
Calculating the Standard Deviation

Define the formula for standard deviation. The standard deviation is a measure of how spread out your data is. It gives you information on how similar each data point is within your sample, which helps you determine if the data is significant. At first glance, the equation may seem a bit complicated, but these steps will walk you through the process of the calculation. The formula is s = √∑((xi – µ)/(N – 1)). s is the standard deviation. ∑ indicates that you will sum all of the sample values collected. xi represents each individual value from your data. µ is the average (or mean) of your data for each group. N is the total sample number.

Average the samples in each group. To calculate the standard deviation, first you must take the average of the samples in the individual groups. The average is designated with the Greek letter mu or µ. To do this, simply add each sample together and then divide by the total number of samples. For example, to find the average grade of the group that read the material before class, let’s look at some data. For simplicity, we will use a dataset of 5 points: 90, 91, 85, 83, and 94. Add all the samples together: 90 + 91 + 85 + 83 + 94 = 443. Divide the sum by the sample number, N = 5: 443/5 = 88.6. The average grade for this group is 88.6.

Subtract each sample from the average. The next part of the calculation involves the (xi – µ) portion of the equation. You will subtract each sample from the average just calculated. For our example you will end up with five subtractions. (90 – 88.6), (91- 88.6), (85 – 88.6), (83 – 88.6), and (94 – 88.6). The calculated numbers are now 1.4, 2.4, -3.6, -5.6, and 5.4.

Square each of these numbers and add them together. Each of the new numbers you have just calculated will now be squared. This step will also take care of any negative signs. If you have a negative sign after this step or at the end of your calculation, you may have forgotten this step. In our example, we are now working with 1.96, 5.76, 12.96, 31.36, and 29.16. Summing these squares together yields: 1.96 + 5.76 + 12.96 + 31.36 + 29.16 = 81.2.
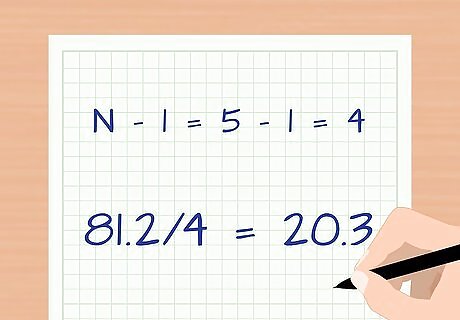
Divide by the total sample number minus 1. The formula divides by N – 1 because it is correcting for the fact that you haven’t counted an entire population; you are taking a sample of the population of all students to make an estimation. Subtract: N – 1 = 5 – 1 = 4 Divide: 81.2/4 = 20.3

Take the square root. Once you have divided by the sample number minus one, take the square root of this final number. This is the last step in calculating the standard deviation. There are statistical programs that will do this calculation for you after inputting the raw data. For our example, the standard deviation of the final grades of students who read before class is: s =√20.3 = 4.51.
Determining Significance

Calculate the variance between your 2 sample groups. Up to this point, the example has only dealt with 1 of the sample groups. If you are trying to compare 2 groups, you will obviously have data from both. Calculate the standard deviation of the second group of samples and use that to calculate the variance between the 2 experimental groups. The formula for variance is sd = √((s1/N1) + (s2/N2)). sd is the variance between your groups. s1 is the standard deviation of group 1 and N1 is the sample size of group 1. s2 is the standard deviation of group 2 and N2 is the sample size of group 2. For our example, let’s say the data from group 2 (students who didn’t read before class) had a sample size of 5 and a standard deviation of 5.81. The variance is: sd = √((s1)/N1) + ((s2)/N2)) sd = √(((4.51)/5) + ((5.81)/5)) = √((20.34/5) + (33.76/5)) = √(4.07 + 6.75) = √10.82 = 3.29.

Calculate the t-score of your data. A t-score allows you to convert your data into a form that allows you to compare it to other data. T-scores allow you to perform a t-test that lets you calculate the probability of two groups being significantly different from each other. The formula for a t-score is: t = (µ1 – µ2)/sd. µ1 is the average of the first group. µ2 is the average of the second group. sd is the variance between your samples. Use the larger average as µ1 so you will not have a negative t-value. For our example, let’s say the sample average for group 2 (those who didn’t read) was 80. The t-score is: t = (µ1 – µ2)/sd = (88.6 – 80)/3.29 = 2.61.

Determine the degrees of freedom of your sample. When using the t-score, the number of degrees of freedom is determined using the sample size. Add up the number of samples from each group and then subtract two. For our example, the degrees of freedom (d.f.) are 8 because there are five samples in the first group and five samples in the second group ((5 + 5) – 2 = 8).

Use a t table to evaluate significance. A table of t-scores and degrees of freedom can be found in a standard statistics book or online. Look at the row containing the degrees of freedom for your data and find the p-value that corresponds to your t-score. With 8 d.f. and a t-score of 2.61, the p-value for a one-tailed test falls between 0.01 and 0.025. Because we set our significance level less than or equal to 0.05, our data is statistically significant. With this data, we reject the null hypothesis and accept the alternative hypothesis: students who read the material before class get better final grades.
Consider a follow up study. Many researchers do a small pilot study with a few measurements to help them understand how to design a larger study. Doing another study, with more measurements, will help increase your confidence about your conclusion. A follow-up study can help you determine if any of your conclusions contained type I error (observing a difference when there isn’t one, or false rejection of the null hypothesis) or type II error (failure to observe a difference when there is one, or false acceptance of the null hypothesis).
















Comments
0 comment